polar H10で、心拍数(bpm)を取ろうかなと思ったら、.edfファイルだった
ミッション : .edfからbpmを取得せよ
pythonでやりたい。
edfファイルとは、心拍データなど生体信号に使用されるデータで、拡張子が.edfとなっている。
このデータをcsvファイルのように直接見ることは出来ないが、Pythonではいくつかのパッケージがある。
インポート
下のコードで使うもの
import pyedflib import biosppy import matplotlib.pyplot as plt from statistics import mean import pandas as pd import japanize_matplotlib from datetime import datetime,timedelta from scipy.signal import resample import matplotlib.dates as mdates
edfファイルを読み込む
使用するパッケージ : pyedflib
PyEDFlib -EDF/BDF Toolbox in Python — PyEDFlib Documentation
filename = 'edfファイルパス' file = pyedflib.EdfReader(filename)
心拍のチャンネルを取得
edfファイルには、チャンネルと呼ばれるものがあり、異なるセンサーや電極から記録される個々の信号は各チャンネルごとに各センサーのデータがまとまっています。 edfファイルから特定の信号(今回はECG)を取得するためには、チャンネルを指定する必要がある。 ここでは、自作関数を使ってECG チャンネルを特定・抽出しています。
# ECGデータが含まれるチャンネルを特定 def find_ecg_channel(file): # EDFファイル内のすべてのチャンネルラベルを取得する channel_labels = file.getSignalLabels() # ECGデータが含まれるチャンネルを特定する for i, label in enumerate(channel_labels): if 'ECG' in label: return i # ECGデータが含まれるチャンネルが見つからない場合は、Noneを返す return None ecg_channel = find_ecg_channel(file)
心拍と心拍数の経過時間を取得
edfのチャンネルを取得したので、チャンネルを指定してデータを読み込む。 そして、biosppyのbiosppy.signals.ecg.ecgを使って、心拍と心拍数の経過時間(秒)を取得する。
def detect_heart_rate(signal, sampling_rate): out = biosppy.signals.ecg.ecg(signal, sampling_rate=sampling_rate,show=False,interactive=False) # HeartRateの基準時間とHeartRateのデータのインデックスを返す return out['heart_rate_ts'],out['heart_rate'] if ecg_channel is not None: # チャンネルから信号とサンプリングレートを取得 signal = file.readSignal(ecg_channel) sampling_rate = file.getSampleFrequency(ecg_channel) print('sampling rate',sampling_rate) #信号の軸とHeartRateの取得 ts,heart_rate = detect_heart_rate(signal, sampling_rate) print('ts',ts) print('heart rate',heart_rate) print('bpm',len(heart_rate))
リサンプリング
心拍と心拍数の経過時間を調べることはできたが、このままでは測定機器のサンプリングレートに従っているので、まだBPM(1分あたりの心拍数)とは言えない。 なので、1分間あたりにリサンプリングする。
# オリジナルのデータの長さとサンプリングレートを取得 original_length = len(ts) original_sampling_rate = original_length / ts[-1] #1分あたりでサンプリングレート・1分あたりでサンプリングしたかったら、1 sampling_rate =1/60 # 新しいデータの長さを計算 new_length = int(original_length * (sampling_rate / original_sampling_rate)) # ダウンサンプリング downsampled_ts = resample(ts, new_length) downsampled_heart_rate= resample(heart_rate, new_length)
秒から日付時間へ
*心拍データが長い人用
以上でedfファイルからbpmを取り出すことができたので、matplotlibでプロットしていく。
その前に、長い時間心拍のデータをとっていたら、x軸をわかりづらい'秒'ではなく、日付時間で表したい。
そのため、x軸を秒から日付時間に変換する。そして、dataframeにすることでプロットが楽になる
#ダウンサンプリングされた値をdatetimeの形に直す #測定開始の日付時間(例:2023年6月5日22時7分40秒) base_datetime = datetime(2023, 6, 5, 22, 7, 40) datetimes = [] for i,value in enumerate(downsampled_ts): datetimes.append(base_datetime + timedelta(seconds=i)) datetimes = [value.strftime('%Y-%m-%d %H:%M:%S') for value in datetimes] #pandasの形に直す heart_rate_df = pd.DataFrame(downsampled_heart_rate_h10) heart_rate_df = heart_rate_df.set_index(pd.to_datetime(datetimes))
matplotlibでプロット
#グラフを表示する領域を,figオブジェクトとして作成。 fig = plt.figure(figsize = (10,6), facecolor='lightblue') ax = fig.add_subplot() ax.plot(heart_rate_df) #axのx軸ラベルを指定 # 開始日時と終了日時をdatetimeオブジェクトとして表現 start_datetime = datetime(2023, 6, 5, 22, 7, 40) end_datetime = datetime(2023, 6, 5, 22, 48, 1) # 5分ごとの日時をリストに格納 time_range_5min = [] current_time = start_datetime while current_time <= end_datetime: time_range_5min.append(current_time) #minutesを変えることで、何分ごとにx軸を表示するかを決める current_time += timedelta(minutes=5) # datetimeオブジェクトを数値に変換 time_range_5min_num = [mdates.date2num(dt) for dt in time_range_5min] # x軸の目盛りを設定 ax.set_xticks(time_range_5min_num) # x軸のフォーマッタを設定 ax.xaxis.set_major_formatter(mdates.DateFormatter('%H:%M:%S')) #各subplotにxラベルを追加 ax.set_xlabel('time') #各subplotにyラベルを追加 ax.set_ylabel('bpm(1m)') ax.legend(loc = 'upper right') plt.show()
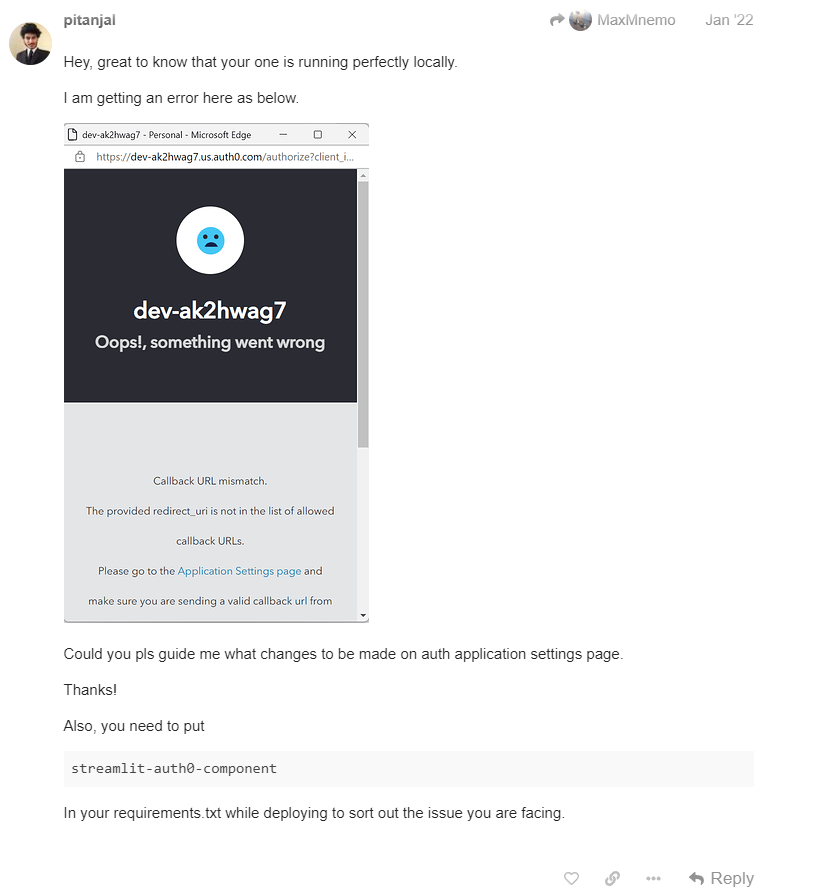
最終結果
うまくいくとこんな感じ

全体コード
import pyedflib import biosppy import matplotlib.pyplot as plt from statistics import mean import pandas as pd import japanize_matplotlib from datetime import datetime,timedelta from scipy.signal import resample import matplotlib.dates as mdates filename = 'edfファイルパス' file = pyedflib.EdfReader(filename) # ECGデータが含まれるチャンネルを特定 def find_ecg_channel(file): # EDFファイル内のすべてのチャンネルラベルを取得する channel_labels = file.getSignalLabels() # ECGデータが含まれるチャンネルを特定する for i, label in enumerate(channel_labels): if 'ECG' in label: return i # ECGデータが含まれるチャンネルが見つからない場合は、Noneを返す return None def detect_heart_rate(signal, sampling_rate): out = biosppy.signals.ecg.ecg(signal, sampling_rate=sampling_rate,show=False,interactive=False) # HeartRateの基準時間とHeartRateのデータのインデックスを返す return out['heart_rate_ts'],out['heart_rate'] ecg_channel = find_ecg_channel(file) if ecg_channel is not None: # チャンネルから信号とサンプリングレートを取得 signal = file.readSignal(ecg_channel) sampling_rate = file.getSampleFrequency(ecg_channel) print('sampling rate',sampling_rate) #信号の軸とHeartRateの取得 ts,heart_rate = detect_heart_rate(signal, sampling_rate) print('ts',ts) print('heart rate',heart_rate) print('bpm',len(heart_rate)) # オリジナルのデータの長さとサンプリングレートを取得 original_length = len(ts) original_sampling_rate = original_length / ts[-1] #1分あたりでサンプリングレート sampling_rate =1/60 # 新しいデータの長さを計算 new_length = int(original_length * (sampling_rate / original_sampling_rate)) # ダウンサンプリング downsampled_ts = resample(ts, new_length) downsampled_heart_rate= resample(heart_rate, new_length) #ダウンサンプリングされた値をdatetimeの形に直す #測定開始の日付時間(例:2023年6月5日22時7分40秒) base_datetime = datetime(2023, 6, 5, 22, 7, 40) datetimes = [] for i,value in enumerate(downsampled_ts): datetimes.append(base_datetime + timedelta(minutes=i)) datetimes = [value.strftime('%Y-%m-%d %H:%M:%S') for value in datetimes] #pandasの形に直す heart_rate_df = pd.DataFrame(downsampled_heart_rate) heart_rate_df = heart_rate_df.set_index(pd.to_datetime(datetimes)) else: print('心拍データが含まれていません') #グラフを表示する領域を,figオブジェクトとして作成。 fig = plt.figure(figsize = (10,6), facecolor='lightblue') ax = fig.add_subplot() ax.plot(heart_rate_df) #axのx軸ラベルを指定 # 開始日時と終了日時をdatetimeオブジェクトとして表現 start_datetime = datetime(2023, 6, 5, 22, 7, 40) end_datetime = datetime(2023, 6, 5, 22, 48, 1) # 5分ごとの日時をリストに格納 time_range_5min = [] current_time = start_datetime while current_time <= end_datetime: time_range_5min.append(current_time) #minutesを変えることで、何分ごとにx軸を表示するかを決める current_time += timedelta(minutes=5) # datetimeオブジェクトを数値に変換 time_range_5min_num = [mdates.date2num(dt) for dt in time_range_5min] # x軸の目盛りを設定 ax.set_xticks(time_range_5min_num) # x軸のフォーマッタを設定 ax.xaxis.set_major_formatter(mdates.DateFormatter('%H:%M:%S')) #各subplotにxラベルを追加 ax.set_xlabel('time') #各subplotにyラベルを追加 ax.set_ylabel('bpm(1m)') plt.show()